

A Workflow for Training Gas Classification Models from BME688 Sensor Data
Digitalisation in brewing has increased the need for reliable and automated process monitoring, particularly during fermentation where gases such as CO₂ and various volatile organic compounds (VOCs) provide important insights. To support this need, a complete Python-based workflow was developed for training machine learning models capable of classifying gases detected by the Bosch BME688 sensor. The workflow is structured into four coordinated scripts—data_preprocessing.py, data_loader.py, neural_net.py, and train.py—each handling a specific stage of the machine-learning pipeline.
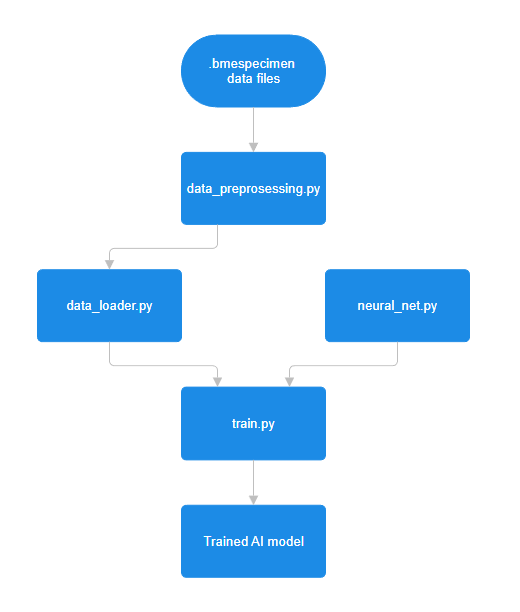
The workflow begins with data_preprocessing.py, which converts the BME AI-Studio output (.bmespecimen files) into a structured format suitable for model training. These files contain sensor readings captured during the BME688 heating cycle, consisting of ten measurement steps repeated throughout the sensing process. The script parses the file’s nested structure, resolves internal links, and constructs lookup tables to simplify access to relevant datapoints. From each cycle, thirteen features are compiled: ten gas-resistance values from the heating steps combined with temperature, humidity, and pressure. The script then groups the parsed samples according to their class labels and divides them into training and validation arrays. Finally, it stores these arrays efficiently in an HDF5 (.h5) file for the next stages of the workflow.
Next, data_loader.py transforms the saved arrays into PyTorch-compatible datasets and dataloaders. It defines a custom dataset class that wraps the features and labels into tensor objects and applies a reproducible random split based on a fixed seed. This ensures that experiments remain consistent across multiple training runs, which is essential when comparing different models or training configurations. The resulting dataloaders shuffle, batch, and stream the data during training, providing an efficient input pipeline for the neural network.
The model architecture and training logic are defined in neural_net.py. This script contains a configurable feedforward neural network built with PyTorch, allowing the user to adjust the number and size of hidden layers. Each layer uses linear transformations, ReLU activation, Batch Normalization, and optional Dropout to improve generalization. Alongside the model, the script implements a ModelTrainer class responsible for executing the learning process. It uses CrossEntropyLoss for classification, the Adam optimizer for efficient gradient-based learning, and the One-Cycle learning rate scheduler, which increases and then decreases the learning rate to encourage fast convergence and stabilised training. The trainer records accuracy and loss during each epoch and generates visual plots summarising the training behaviour.
The workflow is orchestrated by train.py, the top-level script that executes the full pipeline from start to finish. It loads or preprocesses data as needed, initializes datasets and dataloaders, builds the neural network based on user-defined parameters, and runs the full training loop. After training, the script produces performance graphs, computes a confusion matrix, and saves the final trained model for deployment.
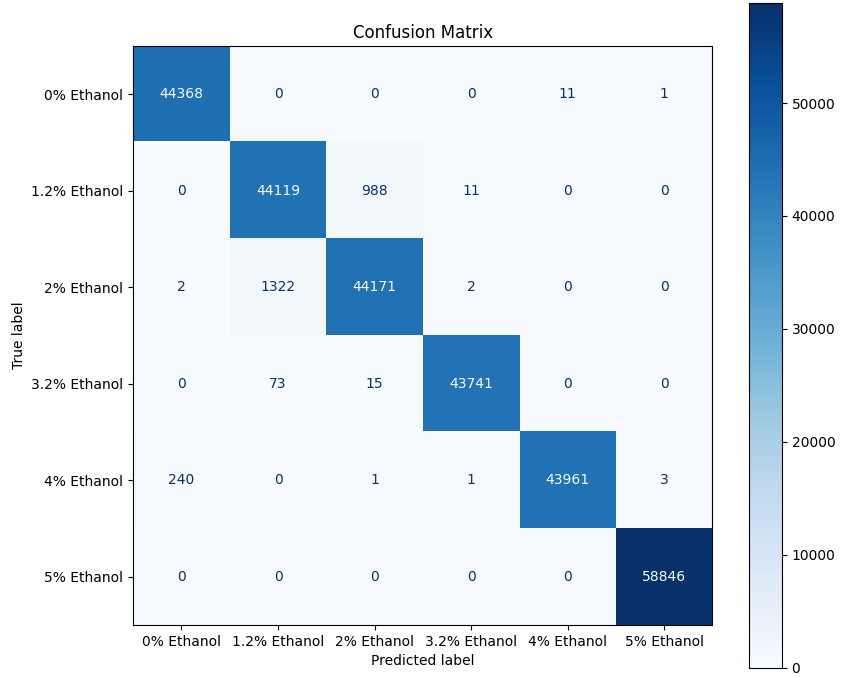
Overall, this workflow provides a flexible and extensible foundation for gas-classification research using the BME688 sensor. By separating preprocessing, data handling, model definition, and orchestration into clear components, the system enables easy experimentation, reproducibility, and future expansion—such as raw-sensor parsing or GPU-accelerated training.