
Balancing Efficiency and Fairness in an AI-Based Student Intervention System
In an era where higher education institutions encounter budget constraints and escalating attrition rates, advanced technology offers a viable solution. This study examines how an artificial intelligence (AI) system can dynamically select and deploy timely interventions, ensuring that student support is both economically sustainable and equitably distributed.
The proposed model focuses on developing a prescriptive Early Intervention System (EIS) designed to optimize student support trajectories. While traditional learning analytics successfully predict academic risk based on historical data, they often fail to provide actionable guidance for educators. To address this limitation, the proposed framework implements prescriptive methodologies. Rather than merely generating an early warning risk score, the AI system functions as an adaptive decision-making engine that learns from continuous interactions, updating operational policies to optimize support for individual learners. To achieve this, the student support journey is modeled as a sequential decision-making problem under uncertainty.
A reinforcement learning (RL) framework was developed utilizing a Markov Decision Process (MDP) to guide institutional resource allocation. Within educational environments, interactions between students and support systems are highly stochastic. For instance, a temporary lapse in platform engagement or a missed communication may stem from situational fatigue rather than an intent to withdraw. The MDP framework accounts for this environmental noise by shifting the optimization focus towards state spaces, action trajectories, and long-term cumulative rewards rather than relying on rigid, rule-based scripts. The network was trained and evaluated using student engagement logs and demographic metadata derived from the Open University Learning Analytics Dataset (OULAD).
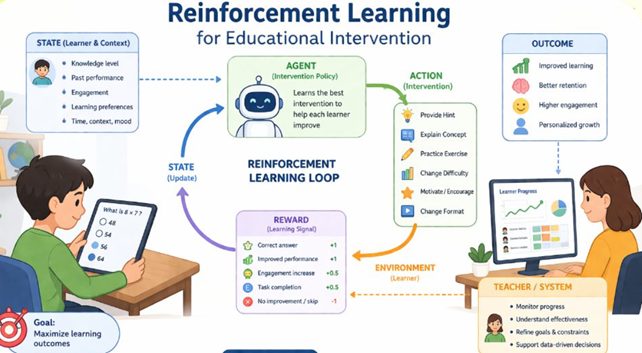
The structural dynamics of this prescriptive workflow and the continuous interaction between the student ecosystem and the AI agent are mapped out in the Reinforcement Learning architecture below.
Figure 1: The Reinforcement Learning Loop implemented in the Early Intervention System, showcasing how student states trigger policy actions and reward signals.
The core computational engine developed in this study relies on a Deep Q-Network (DQN) architecture. Moving beyond static heuristic configurations, the DQN agent derives optimal policies from simulated learning experiences. The deep neural network approximates the optimal action-value function, enabling the system to evaluate highly complex, multi-dimensional student data profiles. A critical technical configuration in this model is the integration of a 0.95 discount factor. This mathematical constraint prevents the agent from solely optimizing for immediate, low-cost actions. Instead, the network evaluates immediate expenditure against long-term academic milestones, recognizing that allocating high-cost resources (such as direct tutoring) at a critical juncture is justified if it maximizes the cumulative probability of successful degree completion.
The action space accessible to the DQN agent is structured around a multi-tier Stepped Care model. Because academic institutions operate with finite financial and human resources, the model learns to dynamically scale interventions across three distinct tiers based on the severity of the student’s academic risk profile:
- Automated nudges (Tier 1): Low-cost, scalable interventions such as automated email alerts or text notifications for initial, minor engagement drops. Experimental simulations demonstrate that these automated nudges comprised approximately 76.5% of the total deployed actions, preserving a significant portion of the operational budget while maintaining continuous learner touchpoints.
- Targeted checking in (Tier 2): Medium-cost efforts, including personalized staff outreach or direct messaging, deployed when a student exhibits persistent difficulties despite receiving lower-tier automated reminders (comprising 5.81% of total actions).
- Intensive support (Tier 3): High-cost, resource-intensive interventions such as one-on-one academic tutoring or specialized professional counseling.
Because Tier 3 represents a highly restricted institutional resource, the trained DQN agent learned a conservative allocation strategy, deploying high-cost interventions in only 17.69% of observed states. The system systematically reserves these high-tier actions for critical, high-risk cases where lower-tier interventions have proven statistically ineffective.
While financial optimization in algorithmic systems frequently risks introducing systemic bias, this study integrates a Fairness-Aware constraint directly into the multi-objective reward function. Standard reinforcement learning agents typically prioritize vulnerable students who require minimal resource investment to pass in order to maximize average institutional performance metrics. This tendency can introduce algorithmic discrimination against highly marginalized student cohorts. The proposed model protects these groups by incorporating the Index of Multiple Deprivation (IMD) and verified disability indicators into the optimization loop. The AI agent receives positive reinforcement for broad retention success, but incurs a severe mathematical penalty if it systematically neglects high-risk, socio-economically marginalized groups to cut short-term costs. This architectural safeguard enforces equitable resource distribution based on human need rather than unconstrained fiscal optimization.
The technical validation involved constructing a custom simulation environment in Python and executing over 32,000 learning episodes to achieve policy convergence. The empirical results indicate that the DQN agent successfully identified an optimal trade-off between institutional cost preservation and student retention. The system managed university support resources with significantly higher efficiency than traditional static rule-based frameworks, maintaining fiscal sustainability while achieving a statistically significant increase in completion rates for vulnerable student subgroups.
However, mirroring the validation challenges observed in generative visual models, real-world deployment requires cautious operationalization. A primary limitation of the current simulation is the assumption that student behavioral responses strictly mirror historical probability distributions. In operational settings, human behavior exhibits deeper psychological complexities that simulated agents cannot fully capture. Furthermore, policy transferability from an offline simulation environment to a live institutional ecosystem introduces friction that demands rigorous validation. Both constraints underscore the necessity for localized, empirical field testing.
Ultimately, artificial intelligence serves to complement educators in this modern era. By taking over routine data processing and multi-tier scheduling, the system frees human advisors to dedicate their energy to building empathetic, high-impact relationships with students. This approach offers higher education a scalable, sustainable model for personalized care, ensuring every student receives precisely calibrated support to prevent academic failure while eliminating institutional resource waste.
The complete journey and core breakthroughs of this prescriptive approach, from data-driven insights to the harmony between human mentorship and ethical AI automation, are visually synthesized in the dashboard below.

Figure 2: A visual summary of the prescriptive student intervention framework, balancing institutional resources and educational equity.
Bibliography
Nguyen, H. 2026. Balancing Efficiency and Fairness in an AI-Based Student Intervention System. Talk by Students. Turku: Turku University of Applied Sciences. Accessed 26.05.2026. https://www.theseus.fi/handle/10024/916369